728x90
반응형
단순한 데이터 생성 코드입니다.
Scikit-learn 에서 제공하는 동방성 정규분포 데이터 생성 함수인 make_blobs 를 사용하였습니다.
샘플 수 400개, 중심점 개수 4개
데이터 시인성을 높이기 위함으로 두 번째 차원의 데이터 순서를 뒤집어 시각화하였음
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()from sklearn.datasets.samples_generator import make_blobs
X,y_true = make_blobs(n_samples=400, centers=4,
cluster_std=0.60, random_state=0)
X=X[:,::-1]
plt.scatter(X[:,0],X[:,1], c='gray', alpha=0.4);
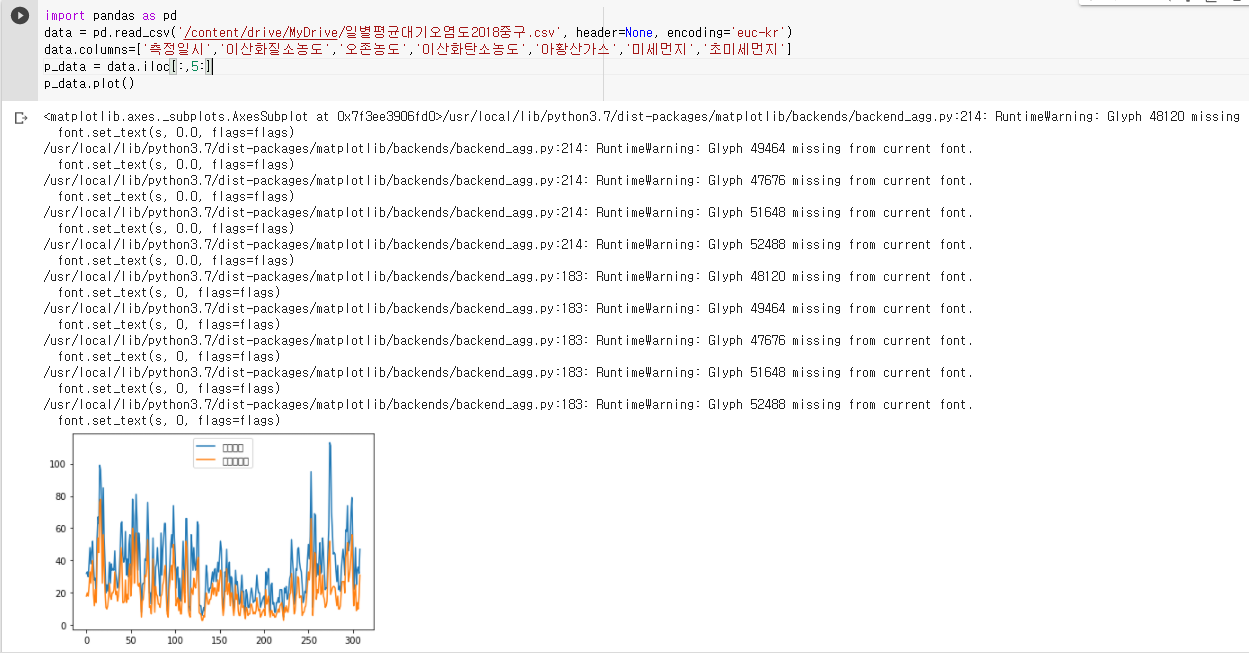
서울시 중구의 일별 평균 대기 오염도 데이터를 시각화 시켜보자 CSV를 읽어와 실행하는 코드를 작성하겠습니다.
# 저의 구글 드라이브로 마운트해줍니다.
from google.colab import drive
drive.mount('/content/drive/')# 판다스를 이용하여 csv 파일을 불러와 그래프화해주기
import pandas as pd
data = pd.read_csv('/content/drive/MyDrive/일별평균대기오염도2018중구.csv', header=None, encoding='euc-kr')
data.columns=['측정일시','이산화질소농도','오존농도','이산화탄소농도','아황산가스','미세먼지','초미세먼지']
p_data = data.iloc[:,5:]
p_data.plot()
)
이후, kind에 bar 를 주어 막대 그래프형식으로 줍니다.
b_data = data.iloc[0:30, 5:]
b_data.plot(kind='bar')

728x90
반응형
'K-MooC > 파이썬 기반 빅데이터 처리 및 분석 기술' 카테고리의 다른 글
| [ KMooc ] 강좌 종료 수료증 (0) | 2021.10.13 |
|---|---|
| [ Python ] Numpy 이해하기 1 (0) | 2021.07.18 |
| Colab을 이용한 환경 구축 - 1 (0) | 2021.07.07 |